
Naive Bayes Classifier is a popular algorithm used in machine learning for classification problems. It is a probabilistic model that is based on Bayes’ theorem with a naive assumption of independence between the features. This algorithm has found applications in various fields, including spam filtering, sentiment analysis, and medical diagnosis. In this article, we will discuss the theory and practice of the Naive Bayes Classifier.
Introduction to Naive Bayes Classifier Algorithm
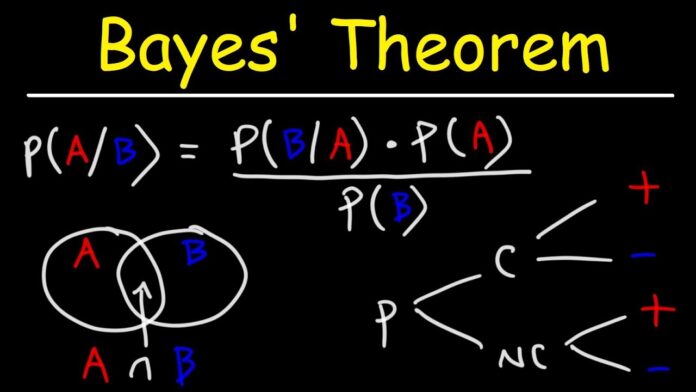
The Naive Bayes Classifier Algorithm is based on Bayes’ theorem, which is a fundamental concept in probability theory. Bayes’ theorem is used to calculate the probability of a hypothesis, given the evidence. In the context of category, the hypothesis is the class label, and the evidence is the feature vector.
It assumes that the features are independent of each other, given the class label. This assumption simplifies the calculation of the probability of the feature vector, given the class label. The probability is calculated using the joint probability of the feature vector and the class label, which is then divided by the probability of the feature vector. The class label with the highest probability is selected as the predicted class label.
Types of Naive Bayes Classifier Algorithm
The Naive Bayes Classifier Algorithm is a probabilistic model used for classification problems. It is based on Bayes’ theorem with an assumption of independence between the features. It is widely used in various fields, including spam filtering, sentiment analysis, and medical diagnosis. There are three main types: Gaussian, Multinomial, and Bernoulli.
Gaussian Naive Bayes

The Gaussian Naive Bayes Algorithm assumes that the features are normally distributed. This means that the probability distribution of each feature follows a Gaussian or normal distribution. The Gaussian Naive Bayes Algorithm is commonly used for continuous data. For example, it can be used for predicting the price of a house based on its size, location, and other features.
Multinomial Naive Bayes
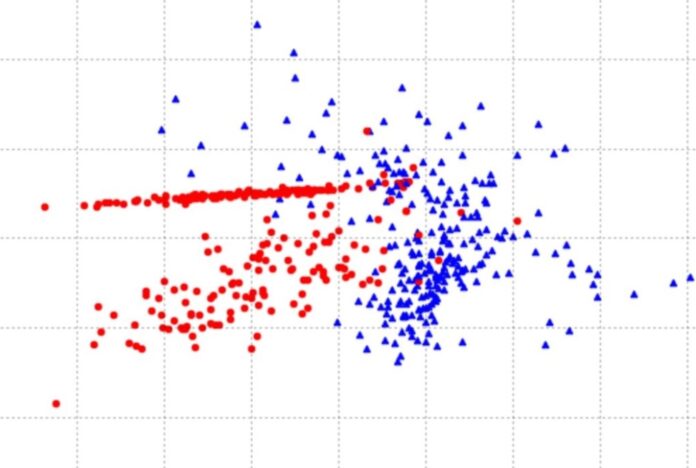
The Multinomial Naive Bayes Algorithm assumes that the features are discrete and follow a multinomial distribution. This means that the features can take on a finite number of values, and the probability distribution is given by a multinomial distribution. It is commonly used for text variety problems. For example, it can be used for sentiment analysis, where the goal is to classify a piece of text as positive, negative, or neutral.
Bernoulli Naive Bayes
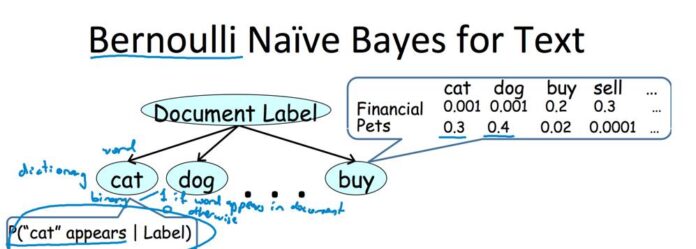
This one assumes that the features are binary and follow a Bernoulli distribution. This means that the features can take on only two values, either 0 or 1. It is commonly used for document-type problems. For example, it can be used for spam filtering, where the goal is to categorize an email as spam or not spam based on the presence or absence of certain words or phrases.
Comparison of the Types
Each type has its strengths and weaknesses. Gaussian Naive Bayes Algorithm is suited for continuous data, whereas Multinomial Naive Bayes Algorithm is suitable for discrete data. Bernoulli Naive Bayes Algorithm is suitable for binary data. The choice of which algorithm to use depends on the nature of the data and the problem at hand.
In terms of performance, the Multinomial Naive Bayes Algorithm generally performs well on text classification problems, whereas the Gaussian Naive Bayes Algorithm is generally the best choice for continuous data. The Bernoulli Naive Bayes Algorithm is best suited for document autonomy problems, where the features are binary.
Training and Testing
Training involves calculating the prior probability and the conditional probability of the feature vector, given the class label. The prior probability is the probability of each class label in the training data, and the conditional probability is the probability of each feature value, given the class label.
Testing involves calculating the probability of the feature vector, given each class label, using the prior and conditional probabilities calculated during training. The class label with the highest probability is selected as the predicted class label.
Performance Evaluation
The performance o is evaluated using various metrics such as accuracy, precision, recall, and F1 score. These metrics measure the effectiveness of the algorithm in correctly classifying the data.
Advantages and Disadvantages
This is a simple yet effective algorithm used for various problems in machine learning. It is based on Bayes’ theorem with an assumption of independence between the features. It has various advantages and disadvantages.
Advantages
- Simple and Easy to Implement: It is simple and easy to implement, making it a popular choice for beginners.
- Works Well with High-Dimensional Data: It works well with high-dimensional data, making it suitable for applications with a large number of features.
- Requires a Small Amount of Training Data: It requires a small amount of training data, making it suitable for applications with limited data.
- Fast and Efficient: It is fast and efficient, making it suitable for applications with large datasets.
- Performs Well on Binary and Categorical Data: It performs well on binary and categorical data, making it suitable for applications such as spam filtering and sentiment analysis.
Disadvantages
- Assumes Features are Independent: It assumes that the features are independent of each other, which is not always the case. This can result in reduced accuracy if the features are not independent.
- Zero-Frequency Problem: It may suffer from the zero-frequency problem, where a feature value does not occur in the training data. This can result in a probability of zero, making it impossible to calculate the probability of the class label given the feature vector.
- May Not Perform Well with Imbalanced Data: It may not perform well with imbalanced data, where one class is much more prevalent than the other. This can result in a biased model that favors the majority class.
- Limited Expressive Power: It has limited expressive power, meaning that it may not be able to capture complex relationships between the features and the class label.
Conclusion
Naive Bayes Classifier Algorithm is a simple and effective algorithm for classification problems. It is widely used in various fields and has proven to be effective in many applications. By understanding the theory and practice, we can leverage this algorithm for our sort problems.







