
The abbreviation NLP stands for Natural Language Processing and describes techniques and methods for machine processing of natural language. The goal is direct communication between humans and computers based on natural language. Typically, the processing is based on the intelligence level of the machine deciphering human messages into meaningful information for it.
Applications that use NLP are all around us. They include Google search, machine translation, chatbots, virtual assistants, etc. If you need professional assistance with the integration of any of NLP techniques into your business project, here is a link to ML developer’s website.
NLP is used in digital advertising, security, and many others. NLP technologies are used both in science and for solving commercial business problems: for example, for research of artificial intelligence and its development, as well as the creation of “smart” systems working with natural human languages, from search engines to music applications.
One of the tasks of language modeling is to predict the next word based on knowledge of the previous text. This is necessary for correcting typos, auto-completion, chatbots, etc. Especially for developers, we have collected four popular NLP models in one place and compared them, relying on documentation and scientific sources. Remember, these are not the only available NLPs, they are simply the most well-known and popular among the developers.
1. BERT
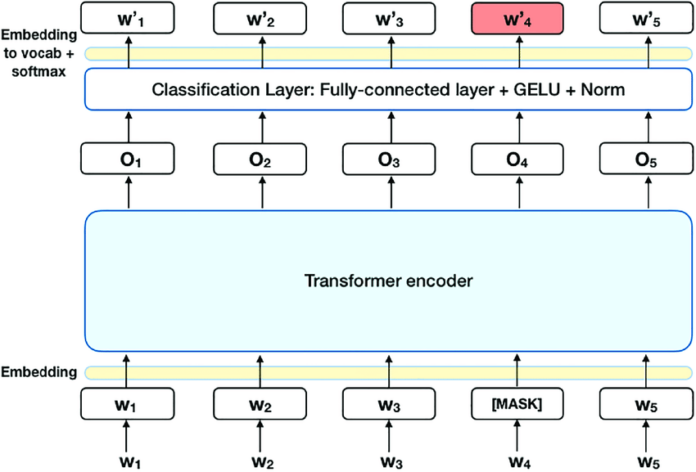
BERT relies on neural networks, and is designed to improve the understanding of natural language queries and the user’s intention behind them. It helps the search engine determine the meaning of words taking into account the context of the entire sentence. Its implementation should allow the search to learn to find more relevant web pages, and users to ask more natural queries.
BERT is open source, available for research, and can be used to train other language analysis systems.
A key feature of BERT is bidirectional learning. Traditional algorithms for a better understanding of the meaning and relevance of a phrase check the sequence of words in a sentence in only one direction (from left to right or from right to left). In contrast, BERT analyzes the entire content of the sentence – both before and after the word, including prepositions and relationships between words. Such a model can determine the meaning of the request more accurately, taking into account the entire context and solving specific user tasks.
Using BERT will make Google search generally more efficient, primarily for long natural, spoken language queries, especially for phrases with prepositions.
However, BERT is not the only DL network that shows excellent results in solving NLP problems, although it may be the most popular. Many NLP models are based on BERT; we will talk about them later.
2. OpenAI’s GPT- 3
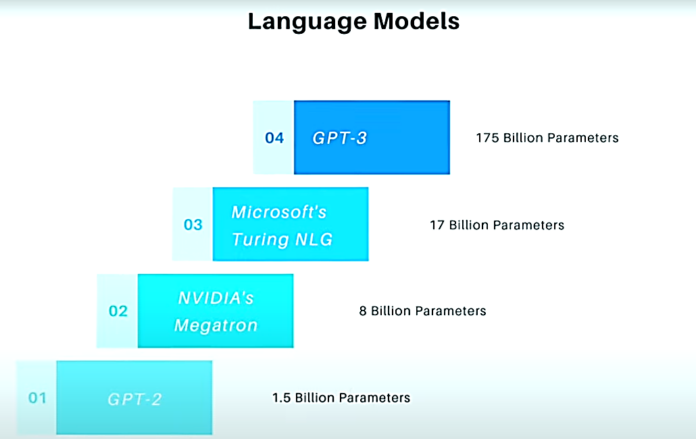
GPT-3 is the most famous of the modern neural network models of the language. You can find a lot of myths about it, but the model knows how to impress. She does an excellent job of writing essays on a given topic, successfully answers questions, and also writes poetry and program code.
The GPT-3 model based on the same architecture as the previous GPT-2 model but 116 times more complex: it uses 175 billion parameters — the second most powerful Microsoft Turing-NLG language model contains 17 billion parameters, GPT-2 1.5 billion.
GPT-3 is trained on 570 GB of text information, and the size of the trained model is about 700 GB. The training array includes data from the Common Crawl open library, the entire Wikipedia, datasets with books, and useful texts from WebText sites.
As a result, the model can write texts in English that are almost indistinguishable from the human level — for this reason, OpenAI does not open full access to the model, because it is afraid that the technology will be used for disinformation. In June 2020, OpenAI opened private access to developer tools (API) and the GPT-3 model, presented its examples of using the algorithm, and launched a “playground.”
3. RoBERTa
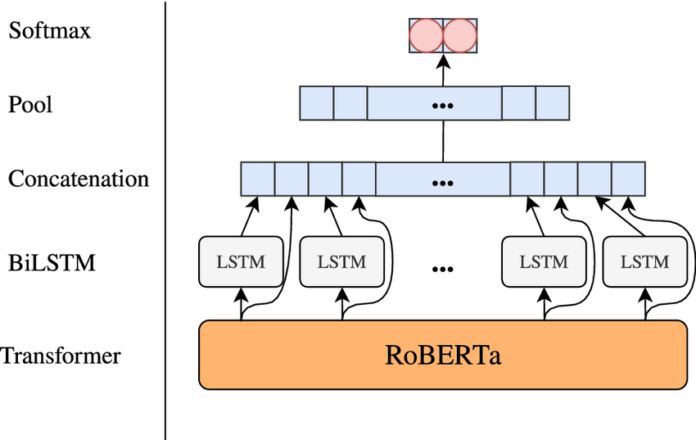
RoBERTa is the name of an optimized pre-learning approach developed by Facebook and the University of Washington. RoBERTa is based entirely on BERT and modifies some learning methods and parameters.
The goal of RoBERTa is to optimize pre-learning with reduced time. Some BERT methods and parameters have been modified and adapted for pre-learning. For example, the developers excluded the prediction of the next sentence from the pre-learning and introduced dynamic masking. In addition, the developers increased the amount of training data tenfold and increased the number of training iterations. RoBERTa achieved excellent results in various NLP benchmarks.
The optimization of the BERT pretraining with RoBERTa shows significant improvements in various NLP benchmarks compared to the original BERT training. In NLP benchmarks such as GLUE, SQuAD, or RACE, RoBERTa achieved previously unattained top scores. For example, RoBERTa achieved a score of 88.5 in the GLUE benchmark. RoBERTa also outperformed XLNet and BERT in the RACE benchmark. The results prove that optimization with RoBERTa can significantly increase the performance of language models for various NLP tasks.
4. CodeBERT
CodeBERT is Microsoft’s NLP model based on BERT. Transformers contain mathematical functions located in interconnected layers and transmit signals from input data and regulate the synaptic power of any connection, just like in all neural networks. All modules of artificial intelligence extract functions and are trained to create monitoring, which transformers take care of, for example, that any output is connected to the input component. The weights between them are calculated dynamically.
Researchers say that Code BERT has achieved high performance both when searching for code in natural language and when developing code for documentation. In the upcoming work, they intend to learn the best generations and more difficult neutral architecture and study goals related to the new generation.
Conclusion
Every improvement in language models contributes to NLP development, from Word2vec to ELMo, from OpenAI GPT to BERT. Thanks to these developments, we can also understand that deep learning as representational learning will be increasingly applied to NLP tasks in the future. They can make full use of current massive data, combine different task scenarios, and train more advanced models to facilitate AI projects. With a well-implemented NLP solution, organizations can provide deeper insights into unstructured data, enhancing business intelligence capabilities.






